ساخت هوش مصنوعی ساده با پایتون: قسمت چهارم، ساخت کلاس شبکه عصبی
بالاخره نوبت به ساخت کلاس شبکه عصبی رسیده است. اما قبل از آن ما فرایند پسانتشار را با بهروزرسانی بایاس شروع میکنیم. ما باید مشتق تابع خطا را نسبت به بایوس حساب کنیم. سپس همینطور رو به عقب ادامه داده و با محاسبه مشتقهای جزیی متغیر bias را پیدا میکنیم.
از آنجایی که ما از انتها به ابتدا حرکت میکنیم، باید مشتق جزیی خطا نسبت به پیشبینی را پیدا کنیم که با متغیر derror_dprediction در تصویر زیر نمایش داده میشود:
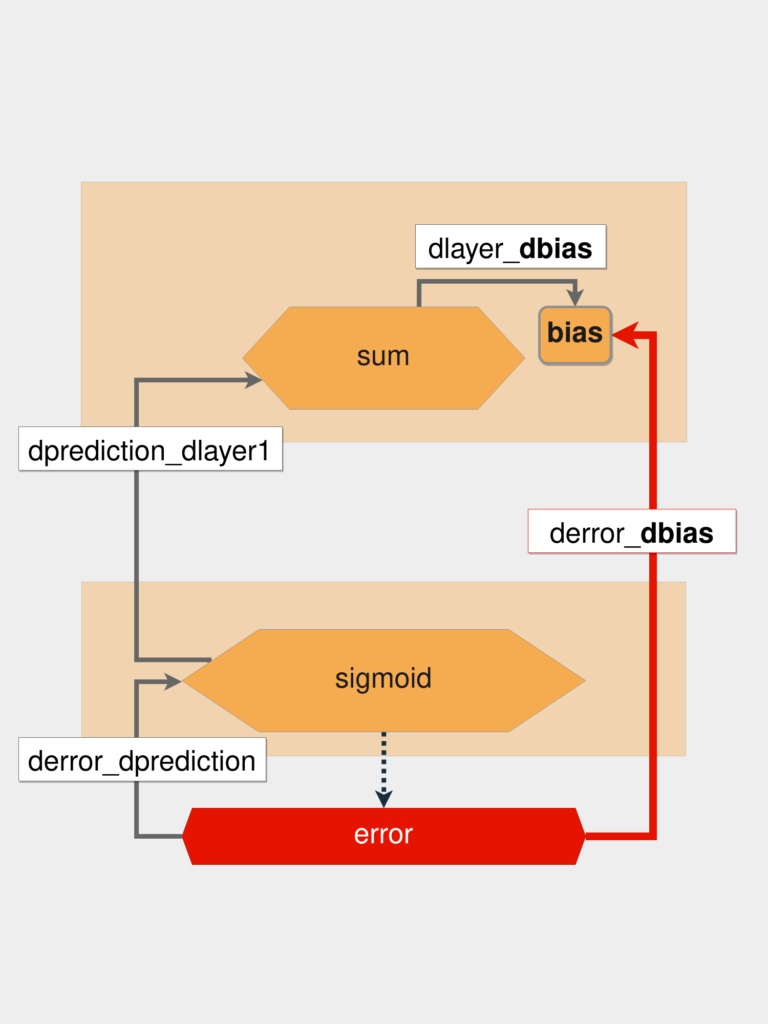
اگر بعد از محاسبه اولین مشتق جزیی (متغیر derror_dprediction) بایاس را پیدا نکردید، باید یک گام دیگر به عقب برگشته و مشتق پیشبینی را نسبت به لایه قبلی (متغیر dprediction_dlayer1) محاسبه کنیم.
مقدار پیشبینی حاصل تابع سیگموید است و برای محاسبه مشتق آن کافی است مقدار زیر را حساب کنیم:
sigmoid(x)*(1 – sigmoid(x))
حالا کافی است مشتق layer_1 را نسبت به بایاس به دست آوریم. حالا و بعد از چند عملیات مقدار متغیر بایاس را داریم که بعد از اجرای قانون توان برابر با ۱ میشود. این فرایند را در قالب کد زیر پیادهسازی میکنیم:
In [36]: def sigmoid_deriv(x):
...: return sigmoid(x) * (1-sigmoid(x))
In [37]: derror_dprediction = 2 * (prediction - target)
In [38]: layer_1 = np.dot(input_vector, weights_1) + bias
In [39]: dprediction_dlayer1 = sigmoid_deriv(layer_1)
In [40]: dlayer1_dbias = 1
In [41]: derror_dbias = (
...: derror_dprediction * dprediction_dlayer1 * dlayer1_dbias
...: )برای بهروزرسانی وزنها هم همین فرایند را باید تکرار کنیم. مشتق ضرب داخلی برابر است با ضرب مشتق بردار اول در بردار دوم بهعلاوه ضرب مشتق بردار دوم در بردار اول.
ساخت کلاس شبکه عصبی
حالا که فرایند بهروزرسانی وزنها و بایاس را فرا گرفتیم، زمان آن رسیده که یک کلاس برای شبکه عصبی بسازیم. وضیفه کلاس NeuralNetwork تولید مقادیر تصادفی اولیه برای وزنها و بایاس است:
class NeuralNetwork:
# ...
def train(self, input_vectors, targets, iterations):
cumulative_errors = []
for current_iteration in range(iterations):
# Pick a data instance at random
random_data_index = np.random.randint(len(input_vectors))
input_vector = input_vectors[random_data_index]
target = targets[random_data_index]
# Compute the gradients and update the weights
derror_dbias, derror_dweights = self._compute_gradients(
input_vector, target
)
self._update_parameters(derror_dbias, derror_dweights)
# Measure the cumulative error for all the instances
if current_iteration % 100 == 0:
cumulative_error = 0
# Loop through all the instances to measure the error
for data_instance_index in range(len(input_vectors)):
data_point = input_vectors[data_instance_index]
target = targets[data_instance_index]
prediction = self.predict(data_point)
error = np.square(prediction - target)
cumulative_error = cumulative_error + error
cumulative_errors.append(cumulative_error)
return cumulative_errorsدر این چند خط کد اتفاقات زیادی در حال جریان است:
خط ۸: یک نمونه تصادفی از دیتاست انتخاب میکند.
خطوط ۱۴ تا ۱۶: متشقهای جزیی را محاسبه کرده و مشتق بایاس و وزنها را به ما میدهد.
خط ۱۸: مقدار بایاس و وزنها را بهروزرسانی میکند.
خط ۲۱: بررسی میکند که آیا ایندکس تکرار در ۱۰۰ ضرب شده یا خیر. این کار برای این است که مقدار تغییر خطا بعد از هر ۱۰۰ تکرار را مشاهده کنیم.
خط ۲۴: یک حلقه که تمام تمام نمونههای داده را بررسی میکند.
خط ۲۸: نتیجه متغیر prediction را محاسبه میکند.
خط ۲۹: مقدار متغیر error برای هر نمونه را محاسبه میکند.
خط ۳۱: در این خط شما مجموع خطاها را با کمک متغیر cumulative_error حساب میکنید.
به طور خلاصه در این کلاس شما یک نمونه تصادفی از دیتاست را انتخاب کرده، گرادیان را محاسبه و وزنها و بایاس را بهروزرسانی میکنید. همچنین شما مجموع خطاها در هر ۱۰۰ تکرار را حساب کرده و از آن برای نمایش میزان تغییر خطا بهره میبرید.
برای ساده کردن کد، ما از یک دیتاست با ۸ نمونه استفاده میکنیم. حالا میتوانیم تابع ()train را فراخوانی کرده و از کتابخانه Matplotlib برای رسم خطای تجمعی هر نمونه استفاده کنیم:
In [45]: # Paste the NeuralNetwork class code here
...: # (and don't forget to add the train method to the class)
In [46]: import matplotlib.pyplot as plt
In [47]: input_vectors = np.array(
...: [
...: [۳, ۱.۵],
...: [۲, ۱],
...: [۴, ۱.۵],
...: [۳, ۴],
...: [۳.۵, ۰.۵],
...: [۲, ۰.۵],
...: [۵.۵, ۱],
...: [۱, ۱],
...: ]
...: )
In [48]: targets = np.array([0, 1, 0, 1, 0, 1, 1, 0])
In [49]: learning_rate = 0.1
In [50]: neural_network = NeuralNetwork(learning_rate)
In [51]: training_error = neural_network.train(input_vectors, targets, 10000)
In [52]: plt.plot(training_error)
In [53]: plt.xlabel("Iterations")
In [54]: plt.ylabel("Error for all training instances")
In [54]: plt.savefig("cumulative_error.png")نمودار زیر مقدار خطای یک نمونه در شبکه عصبی را نشان میدهد:
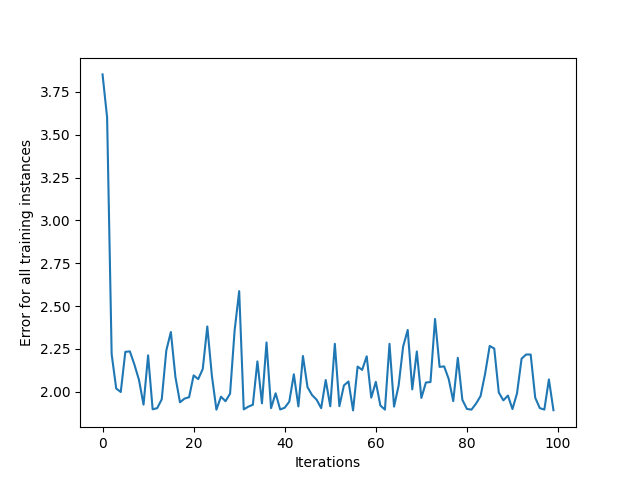
همانطور که میبینید، به طور کلی خطا در حال کاهش است. بعد از یک کاهش بزرگ در ابتدا، مقدار خطا به طور مداوم افزایش و کاهش پیدا میکند. دلیل این اتفاق تصادفی و کوچک بودن دیتاست است که باعث شده شبکه عصبی کار سختی پیش رو داشته باشد.
اما ارزیابی عملکرد بر اساس این شاخص کار درستی نیست چرا که شما شبکه عصبی را بر اساس دادههایی که از قبل دیده میسنجید. این کار منجر به بروز اتفاق بیش برازش (یا Overfitting) میشود که در آن مدل آنقدر خوب با دیتاست آموزشی خوب کار میکند که نمیتواند آن را به دادههای دیگر تعمیم دهد.
اضافه کردن لایههای بیشتر
دیتاست این آموزش بسیار کوچک است. به طور معمول مدلهای یادگیری عمیق به دلیل پیچیدگی دیتاست و وجود دادههای اشتباه، از حجم بزرگی از داده بهره میبرند. از آنجایی که این دیتاستها بسیار بزرگ و پیچیده هستند، استفاده از یک یا دو لایه جوابگوی نیازها نیست. به همین دلیل روی واژه «عمیق» در یادگیری عمیق تاکید میکنیم.
با اضافه کردن لایههای بیشتر قدرت پردازش شبکه عصبی نیز بیشتر شده و قادر به انجام پیشبینیهای سطح بالا است. یکی از انواع این پیشبینیها تشخیص چهره است که در آن شبکه عصبی تصویر شما را با تصویر موجود در دیتاست مقایسه کرده و نقاط مشترک را تشخیص میدهد.
سرویس تشخیص چهره پادیوم با اتکاء بر همین فناوری آماده ارائه به کسبوکارهای متقاضی است. فقط کافی است فرم زیر را پر کنید تا کارشناسان ما در اولین فرصت با شما تماس بگیرند:
در شبکههای اجتماعی به اشتراک بگذارید