ساخت هوش مصنوعی ساده با پایتون: قسمت دوم، توسعه مدل شبکه عصبی
اولین مرحله برای توسعه یک شبکه عصبی تولید خروجی از دادههای ورودی است. این کار با ساخت یک مجموع وزندار از متغیرها انجام میشود. برای شروع باید با استفاده از کتابخانه NumPy در پایتون دادهها را نمایش دهید.
نمایش دادههای شبکه عصبی با NumPy
شما باید از NumPy برای نمایش بردارهای ورودی به عنوان آرایه استفاده کنید. اما قبل از این کار بهتر است کمی با بردارها در پایتون کار کنید تا درک بهتری از فرایند داشته باشید.
در این مثال شما یک بردار ورودی و دو بردار وزن دارید. هدف پیدا کردن برداری است که از نظر جهت و اندازه بیشترین شباهت را با بردار ورودی دارد. بردارها به شکل زیر هستند:
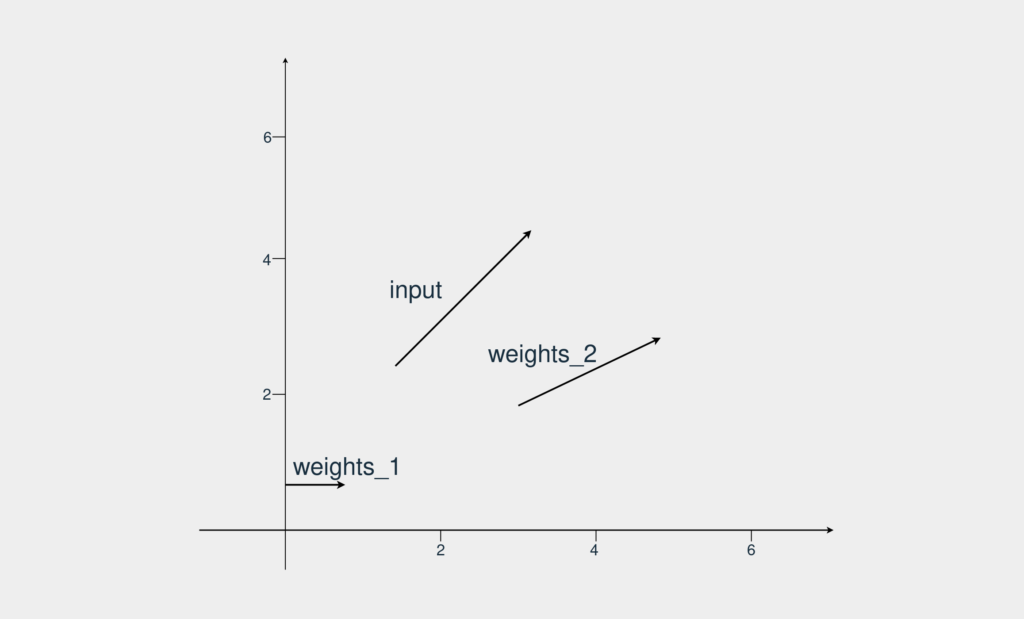
میبینید که weights_2 به بردار ورودی ما شباهت بیشتری دارد. حالا این چطور باید این موضوع را در پایتون بفهمیم؟
اول از همه باید هر سه بردار را تعریف کنید. بعد از آن باید میزان شباهت هر کدام از بردارهای وزن را با بردار ورودی بسنجید. برای این کار از ضرب داخلی استفاده میکنیم. از آنجایی که همه بردارها دو بعدی هستند، باید این مراحل را طی کنیم:
- اولین عدد input_vector را در اولین عدد weights_1 ضرب میکنیم.
- دومین عدد input_vector را در دومین عدد weights_2 ضرب میکنیم.
- نتیجه هر دو ضرب را جمع میکنیم.
برای انجام این مراحل در پایتون ابتدا باید یک محیط مجازی درست کنیم. پایتون ۳.۳ به بعد با venv. ارائه میشوند و کافی است در شل دستورات زیر را اجرا کنید:
$ python -m venv ~/.my-env
$ source ~/.my-env/bin/activateحالا باید کنسول IPython را با کمک pip نصب کنیم. از آنجایی که به NumPy و Matplotlib نیز نیاز داریم، آنها را هم نصب میکنیم.
(my-env) $ python -m pip install ipython numpy matplotlib
(my-env) $ ipythonحال از کد زیر در پایتون برای محاسبه ضرب داخلی input_vector و weights_1 استفاده میکنیم:
In [1]: input_vector = [1.72, 1.23]
In [2]: weights_1 = [1.26, 0]
In [3]: weights_2 = [2.17, 0.32]
In [4]: # Computing the dot product of input_vector and weights_1
In [5]: first_indexes_mult = input_vector[0] * weights_1[0]
In [6]: second_indexes_mult = input_vector[1] * weights_1[1]
In [7]: dot_product_1 = first_indexes_mult + second_indexes_mult
In [8]: print(f"The dot product is: {dot_product_1}")
Out[8]: The dot product is: 2.1672ضریب داخلی برابر با ۲/۱۶۷۲ است. ما میتوانیم از کلاس ()np.dot در NumPy برای محاسبه ضرب داخلی استفاده کنیم:
In [9]: import numpy as np
In [10]: dot_product_1 = np.dot(input_vector, weights_1)
In [11]: print(f"The dot product is: {dot_product_1}")
Out[11]: The dot product is: 2.1672در گام بعد باید ضرب داخلی input_vector و weights_2 را محاسبه کنیم:
In [10]: dot_product_2 = np.dot(input_vector, weights_2)
In [11]: print(f"The dot product is: {dot_product_2}")
Out[11]: The dot product is: 4.1259این بار به عدد ۴/۱۲۵۹ میرسیم. از آنجایی که این عدد بزرگتر از ضرب داخلی قبلی است، پس نتیجه میگیریم input_vector و weights_2 بیشتر به یکدیگر شبیه هستند.
در ادامه با هم مدلی میسازیم که فقط دو خروجی دارد. نتیجه یا ۰ است یا ۱. این مسئله دستهبندی که یکی از زیرمجموعههای یادگیری با ناظر است که در آن شما یک مجموعه داده با وروردیها و اهداف مشخص دارید. جدول زیر ورودیها و خروجیهای دیتاست را نشان میدهد:
| بردار ورودی | هدف |
| [۱/۵۶، ۱/۶۶] | ۱ |
| [۱/۵، ۲] | ۰ |
هدف در واقع متغیری است که میخواهید آن را پیشبینی کنید. دیتاست در این مثال تنها شامل اعداد است، اما در کاربردهای واقعی دیتاستها گاهی به صورت فایل شامل عکس و متن ارائه میشوند.
اولین پیشبینی
برای این تمرین ما یک شبکه عصبی با دو لایه میسازیم. تا به اینجا از دو عملیات ضرب داخلی و جمع استفاده کردهایم که هر دو عملیاتهای خطی هستند. اگر شما لایه های بیشتری اضافه کنید اما تنها از عملیاتهای خطی بهره ببرید، خروجی تغییری نخواهد داشت، چرا که هر لایه با لایه قبلی همبستگی دارد. از این رو به ازای هر شبکه عصبی با چندین لایه، یک شبکه عصبی با لایههای کمتر وجود دارد که همان کار را انجام میدهد.
کاری که شما باید انجام دهید این است که یک عملیات پیدا کنید که گاهی باعث همبستگی لایههای میانی با ورودیها شود و گاهی نیز این همبستگی را نشان ندهد. این امر با استفاده از توابع غیرخطی ممکن میشود. به این توابع غیر خطی، توابع فعالسازی میگوییم.
شبکه عصبی که ما در حال ساخت آن هستیم از تابع سیگموید استفاده میکند. این تابع خروجی را به طیفی بین ۰ تا ۱ محدود میکند. فرمول تابع سیگموید را در زیر میبینید:
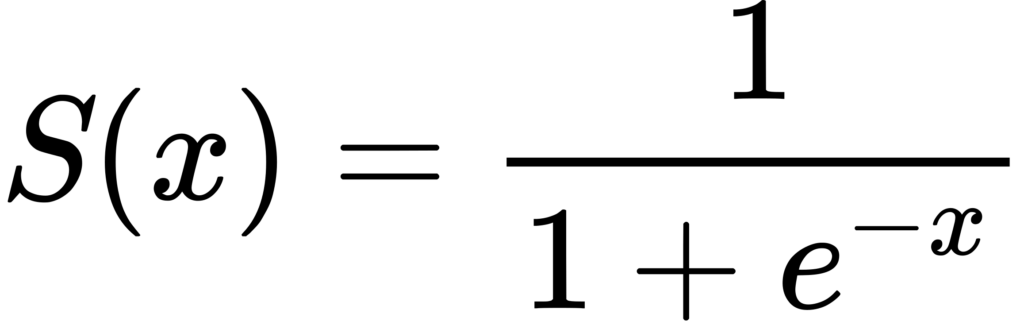
ثابت e در این تابع عدد اویلر نام دارد و شما می توانید از کلاس (np.exp(x برای محاسبه eˣ استفاده کنید. از آنجایی که این تابع خروجی را به عددی بین ۰ تا ۱ محدود میکند، از آن برای پیشبینی احتمالات استفاده میکنیم. اگر عدد بالاتر از ۰/۵ بود، آن را ۱ و اگر پایینتر بود آن را ۰ در نظر میگیریم.
شکل زیر محاسبات داخلی شبکهای که در حال ساخت آن هستید را نشان می دهد.
حالا باید این اطلاعات را به کد تبدیل کنیم. کد زیر توابع نشاندادهشده در بالا را نشان میدهد:
In [12]: # Wrapping the vectors in NumPy arrays
In [13]: input_vector = np.array([1.66, 1.56])
In [14]: weights_1 = np.array([1.45, -0.66])
In [15]: bias = np.array([0.0])
In [16]: def sigmoid(x):
...: return 1 / (1 + np.exp(-x))
In [17]: def make_prediction(input_vector, weights, bias):
...: layer_1 = np.dot(input_vector, weights) + bias
...: layer_2 = sigmoid(layer_1)
...: return layer_2
In [18]: prediction = make_prediction(input_vector, weights_1, bias)
In [19]: print(f"The prediction result is: {prediction}")
Out[19]: The prediction result is: [0.7985731]نتیجه عدد ۰/۷۹ است به این ترتیب خروجی ۱ میشود. شبکه ما پیشبینی درست را انجام داده است. حالا بردار دوم را امتحان میکنیم. خروجی درست برای این بردار ۰ است.
In [20]: # Changing the value of input_vector
In [21]: input_vector = np.array([2, 1.5])
In [22]: prediction = make_prediction(input_vector, weights_1, bias)
In [23]: print(f"The prediction result is: {prediction}")
Out[23]: The prediction result is: [0.87101915]میبینیم که این بار مدل خروجی را اشتباه پیشبینی کرده است. اما این پیشبینی چقدر اشتباه بوده؟ در پست بعدی راهی برای اندازهگیری میزان اشتباه و آموزش مدل پیدا میکنیم.
در شبکههای اجتماعی به اشتراک بگذارید